Recommendation
추천 시스템에서는 사용자 A와 유사한 사용자 A’을 찾아서 A’이 선호하는 제품을 A에게 추천해주어야 한다. 그렇다면 A와 A’, 그리고 B와 B’의 관계 중에서 무엇의 유사도가 더 큰지 어떻게 비교할 수 있을까?
먼저 Shortest path를 이용하는 방법이 있다. 즉, 거리가 가까울수록 유사도를 더 높게 매기는 것이다. 하지만 이 방식으로는 Common neighbor의 수는 고려하지 못한다.
이를 해결하기 위해 Personalized PageRank / Random Walk with Restarts를 사용한다.
Proximity on Graphs
이번 강의에서 그래프 내에서의 유사도를 구하기 위해 아래 3가지 방법을 비교해 볼 것이다.
-
PageRank
-
Personalized PageRank
-
Random Walks with Restarts
먼저 이전에 이미 다루었던 PageRank에 대해 이야기 해 보자. PageRank는 Node를 중요도에 따라 순위를 매긴다. 그리고 walk 도중 Network 내의 랜덤한 Node로 순간이동한다.
Personalized PageRank도 이와 거의 동일하다. 유일한 차이점은 순간이동을 할 때, Network 내의 모든 Node가 아닌 정해진 Subset S로만 이동한다는 것이다.
마지막 Random Walks with Restarts는 특정 Node Item Q에 대한 유사도를 측정하기 위해 위에서 언급한 Subset S를 Node Q로만 한정하는 방식이다. 즉, Random Walk 도중 일정 확률로 시작지점으로 돌아오는 것이다.
Random Walks
Random Walks의 간략한 알고리즘은 아래와 같다.
- QUERY_NODES에서 시작하여 Random한 neighbor에게 step을 이동한다.
- 해당 node의 visit count를 저장한다.
- ALPHA의 확률로 walk를 QUERY_NODES 중 한곳에서 restart 한다.
- walk가 끝나고 가장 높은 visit count를 가진 node가 QUERY_NODES와 가장 가깝다.
아래는 이러한 알고리즘을 pseudo code로 나타낸 예시이다.

아래의 그림과 같이 User들과 Item들로 구성된 bipartite graph에서, 한 step마다 Item에서 random User로, 그리고 User와 연결된 random Item으로 이동하여, 해당 Item에 방문한 횟수를 통해 Query Item Q와의 유사도를 측정한다.
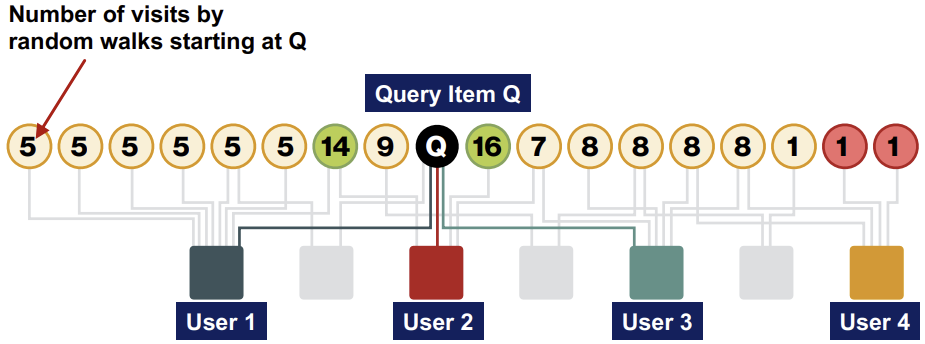
장점
이러한 알고리즘은 유사도를 측정하는 과정에서 우리가 중요하게 생각하는 아래의 요소들을 모두 포함하고 있기 때문에 좋은 solution이다.
- Multiple connections
- Multiple paths
- Direct and indirect connections
- Degree of the node
PageRank의 변형 알고리즘 Summary

Summary

출처, 더 궁금하다면?
Stanford CS224W: Machine Learning with Graphs | 2021 | Lecture 4.3 - Random Walk with Restarts