Relational Classification
기본적인 아이디어는 이웃 Node들의 Class 확률의 weighted average를 이용하여 Node \(v\)의 Class 확률 \(Y_v\)를 구하는 것이다.
레이블이 있는 Node는 레이블의 값(\(Y_{v}^*\))으로, 레이블이 없는 Node는 \(Y_{v} = 0.5\)로 초기화 한다.
converge가 일어나거나, 미리 설정해둔 iteration 최대값이 될때까지 업데이트한다. 이 때, Node Label과 Network의 구조만 활용하고, Node attribute는 사용하지 않는다.
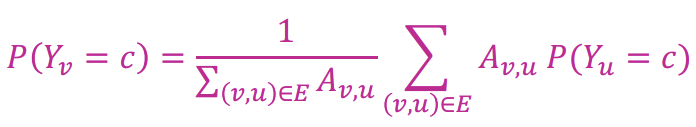
위는 업데이트에 대한 공식으로, Node \(v\)가 레이블 \(c\)를 가질 확률(\(P(Y_{u} = c)\))은 이웃 Node들이 레이블 \(c\)를 가질 확률의 합을 degree로 나눈 값, 즉 평균이라고 정한다. 이때, 경우에 따라 \(A_{v,u}\)를 곱해 weight를 부여한다.
이러한 Relational Classification은 Convergence가 보장되어있지 않고, Node feature 정보를 사용하지 않는다는 단점이 있다.
Relational Classification의 예시
아래는 Relational Classification을 초기화하고, Node ID 순서대로 업데이트 하는 예시를 나타내고 있다. 이때, 이미 레이블링 된 Node는 고정으로 두고, 회색 Node만 업데이트를 진행한다.
먼저, 레이블이 없는 Node는 0.5로 초기화한다.
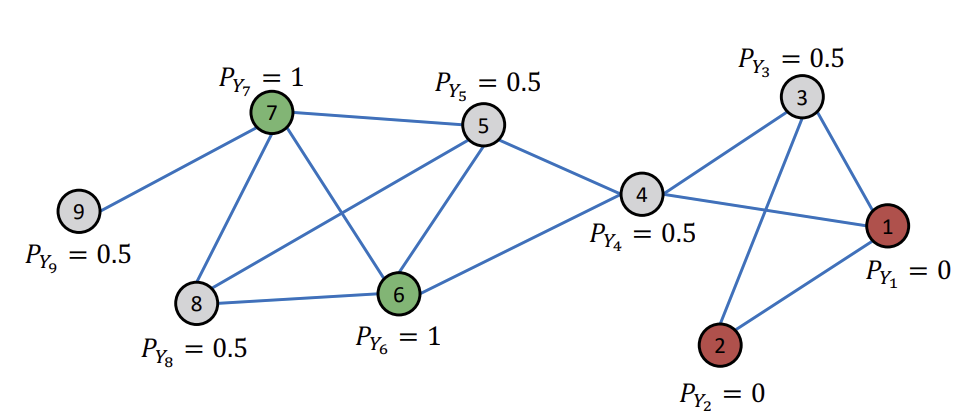
이후, Node ID 순서대로 이웃 Node들의 \(P(Y_{u})\)의 평균값으로 업데이트한다. (Iteration 1)
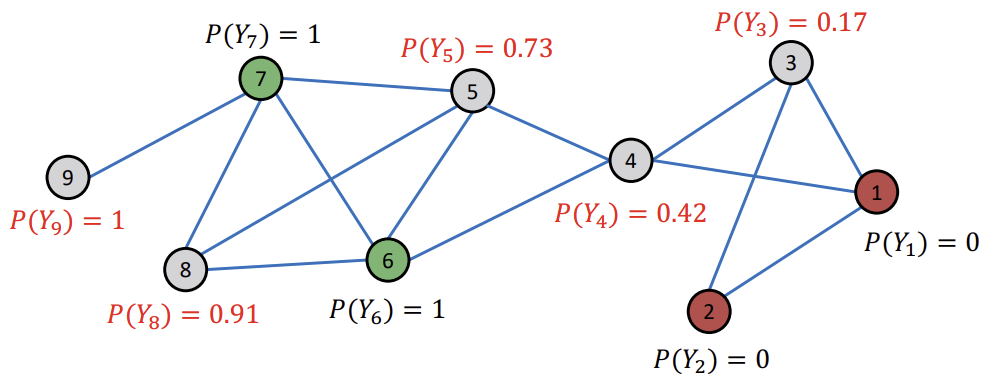
이후, Converge한 Node는 그대로 두고, 아직 Converge되지 않은 Node들에 대해서만 업데이트를 반복한다.
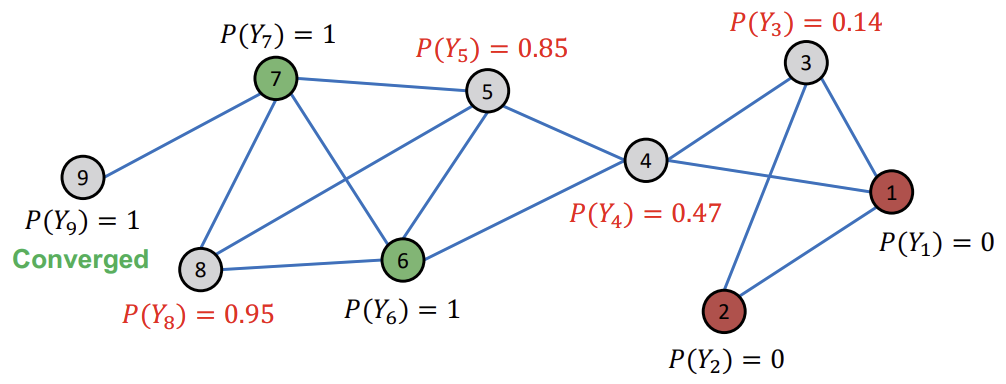
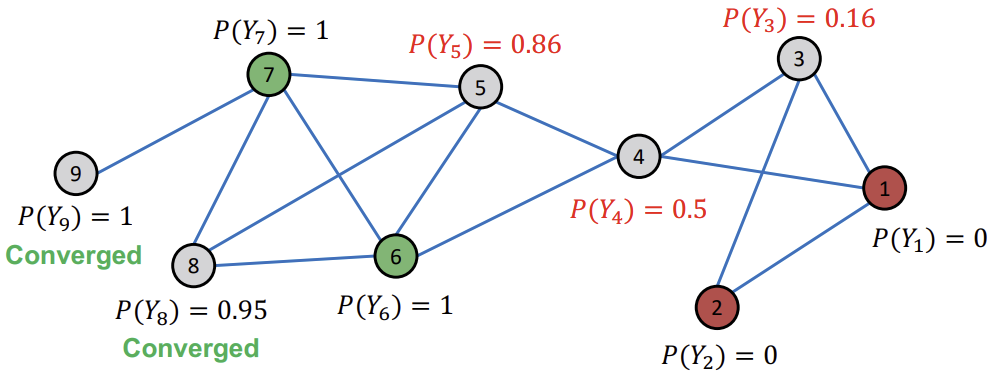
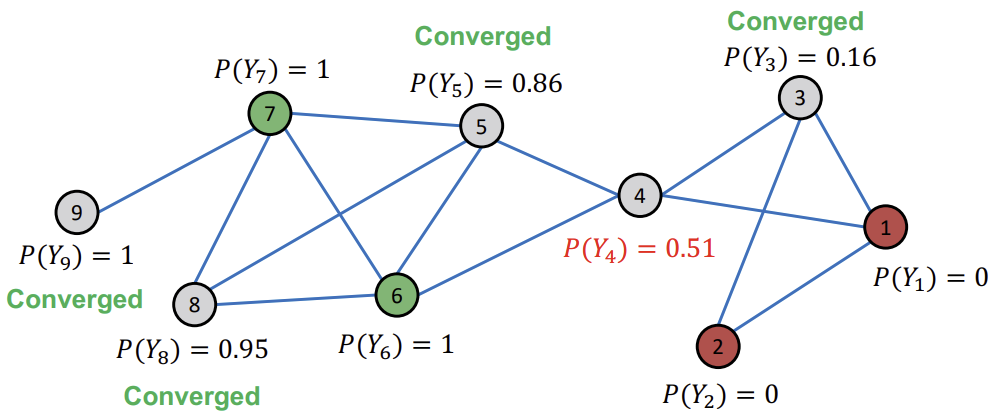
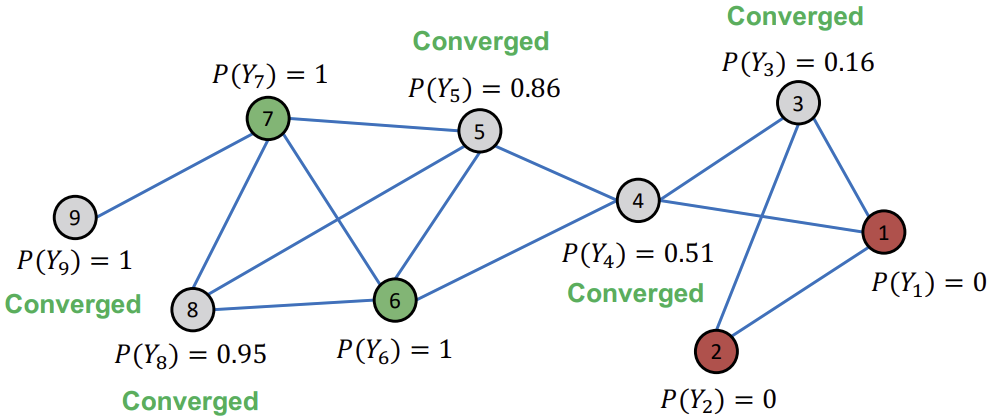
모든 Node들이 Converge 되었다면, \(P(Y_{v}) > 0.5\)인 Node들은 Class1로, \(P(Y_{v}) < 0.5\)인 Node들은 Class0로 배정한다.
하지만 이러한 Relational Classification은 위에서 언급했듯 Node attribute를 전혀 활용하지 않는다. Node attribute를 활용하려면 어떻게 해야할까?
Iterative Classification
Iterative Classification은 Node \(v\)에 대하여 \(f_v\)의 feature vector를 만들고, 이웃 노드의 집합 \(N_v\)의 \(f_v\)에 대한 summary인 \(z_v\)를 활용하여 레이블 \(Y_v\)를 예측한다. 이 과정에서 2개의 Classifier를 사용하는데, 이는 아래와 같다.
- \(\phi_{1}(f_{v})\)
feature vector \(f_v\)만을 사용하여 Node 레이블을 예측한다.
- \(\phi_{2}(f_{v}, z_{v})\)
feature vector \(f_v\)와 Node \(v\)의 이웃의 레이블 summary \(z_v\)를 활용하여 레이블을 예측한다.
이 때, \(z_v\)란 정확하게 무엇을 의미하는 것일까?
\(z_v\)는 기본적으로 vector 형태를 가지며, \(N_v\)에 존재하는 레이블의 수를 기록하거나, 가장 흔한 레이블, 혹은 레이블의 종류의 수를 기록하는 등의 방식으로 summary 역할을 한다.
Iterative Classifier들은 2가지 Phase를 통해 사용된다.
Phase 1 : Node attribute만을 사용하여 Classify (training set)
먼저 \(\phi_{1}(f_{v})\)를 이용하여 \(Y_v\)를 초기화한다. 이를 통해 정해진 \(Y_v\)를 이용해 \(z_{v}\)를 계산하고, \(\phi_{2}(f_{v},z_{v})\)로 \(Y_v\)를 예측한다.
Phase 2 : Iterate till convergence (test set)
위에서와 마찬가지로 \(\phi_{1}\)으로 \(Y_v\)를 구한 후, \(z_{v}\)를 계산하고, \(\phi_{2}\)로 레이블을 예측한다.
이후, \(N_v\)에 속한 \(Y_u\)들이 변하면 다시 \(z_{v}\)를 계산하고, 업데이트 된 \(z_{v}\)를 이용하여 \(Y_u\)를 다시 예측하는 것을 반복한다.
이를 Class 레이블이 stabilize 되거나, 미리 정해둔 max iteration이 충족될 때까지 반복한다.
Iterative Classification의 예시
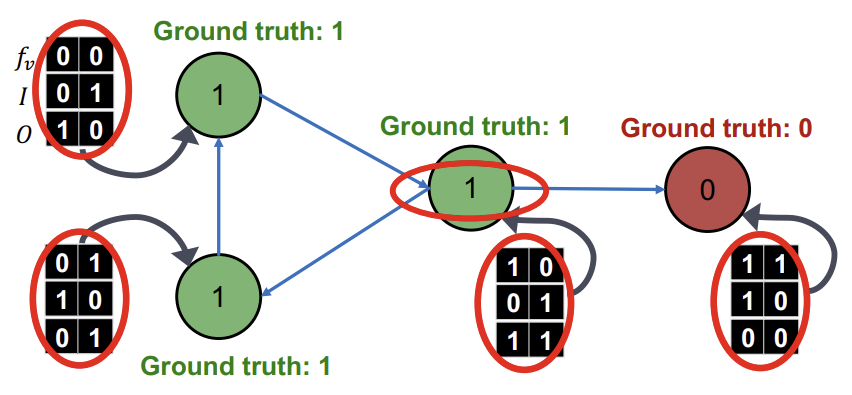
먼저 Node attribute \(f_v\)를 이용하여 \(\phi_{1}\)을 초기화한다. 이 과정에서 가운데 Node가 정답이 1인데 0으로 오답을 출력한 것을 확인할 수 있다.
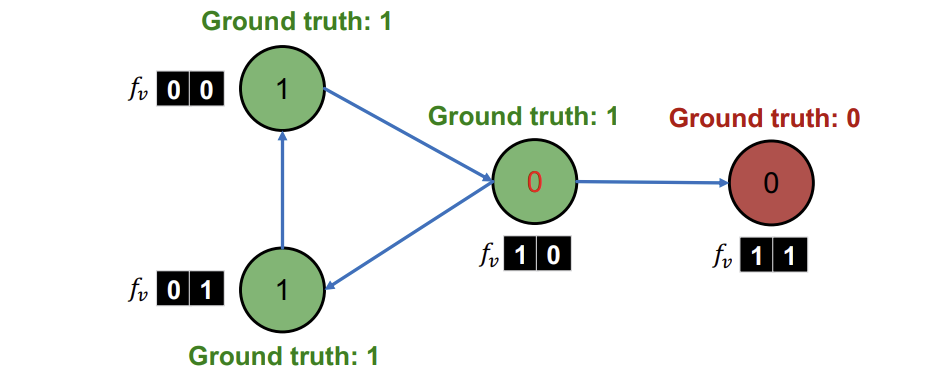
이후, \(\phi_{1}\)으로 예측한 레이블로, vector \(z_v\)를 계산한다. 해당 예시에서는 \(z_v\)에 2가지 요소를 사용했는데, I는 incoming neighbor, O는 outgoing neighbor를 의미하고 각 vector에서 왼쪽 값은 Class0의 수, 오른쪽 값은 Class1의 수를 의미한다.
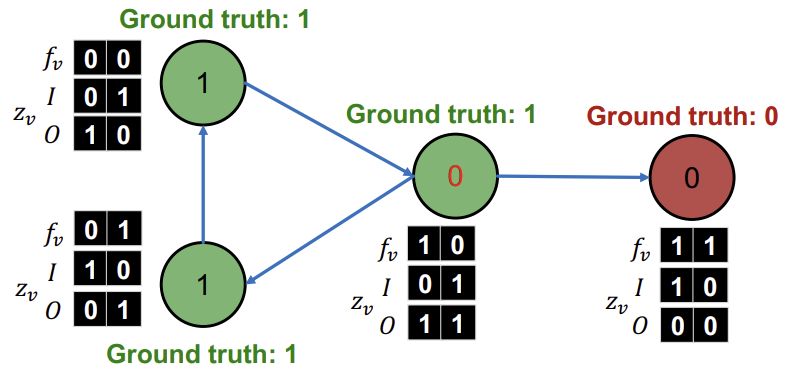
다음으로 step1에서 \(\phi_{1}\)과 \(\phi_{2}\)의 training을 진행한다. 이때, 각 Classifier의 training에는 초록색과 빨간색 동그라미친 부분을 이용한다.
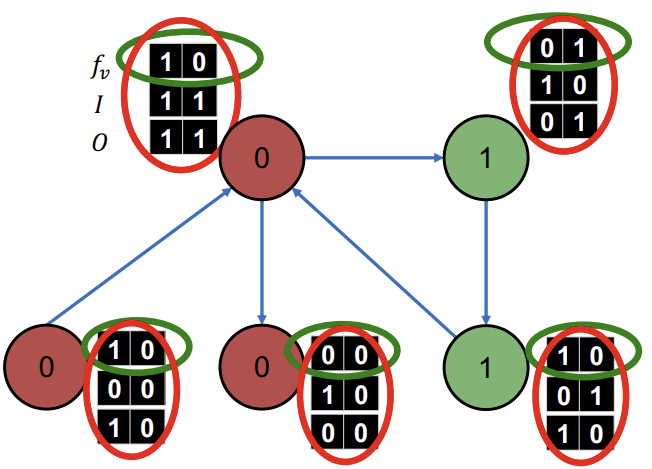
test set인 step2에서는 학습이 완료된 \(\phi_{1}\)으로 초기 \(Y_v\)를 지정한다.
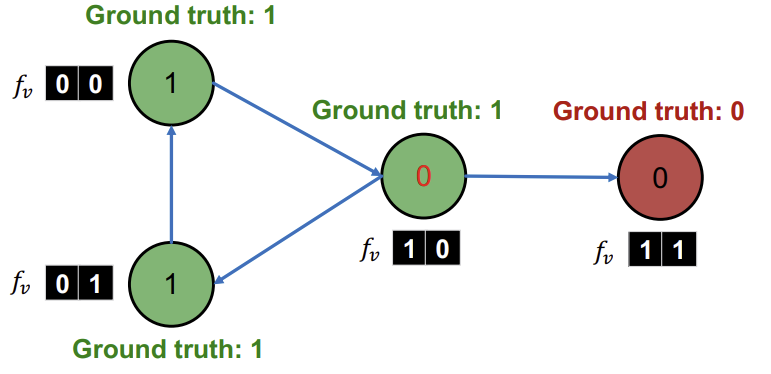
그리고 이전과 마찬가지로 \(z_v\)를 계산하고,
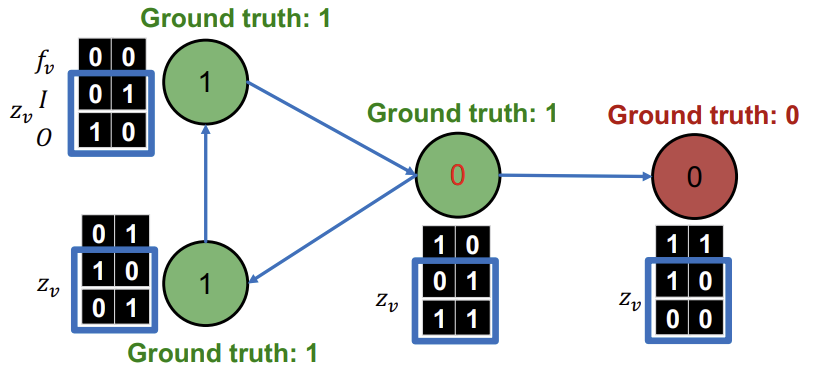
구해진 \(z_v\)를 이용해 \(\phi_{2}\)로 모든 Node들을 다시 Classify한다.
이때, 레이블이 바뀌면 \(z_v\)또한 변하므로, 다시 \(z_v\)를 계산하고,
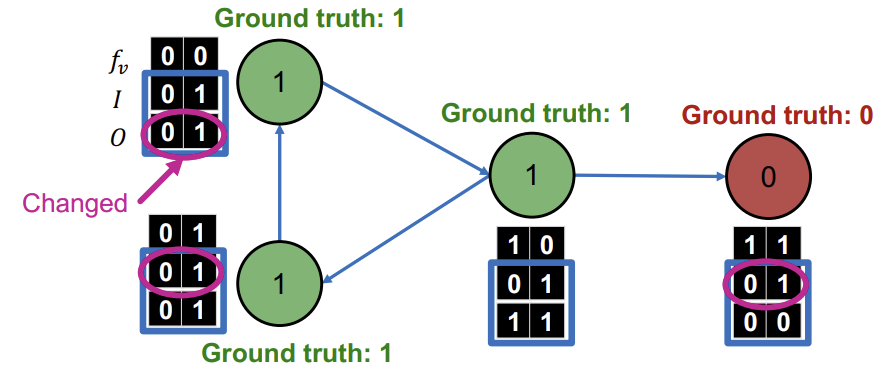
다시 계산한 \(z_v\)를 이용해 \(\phi_{2}\)로 모든 Node들을 다시 Classify하는 과정을 모든 Node Class가 converge되거나 max iteration에 도달할 때까지 반복한다.
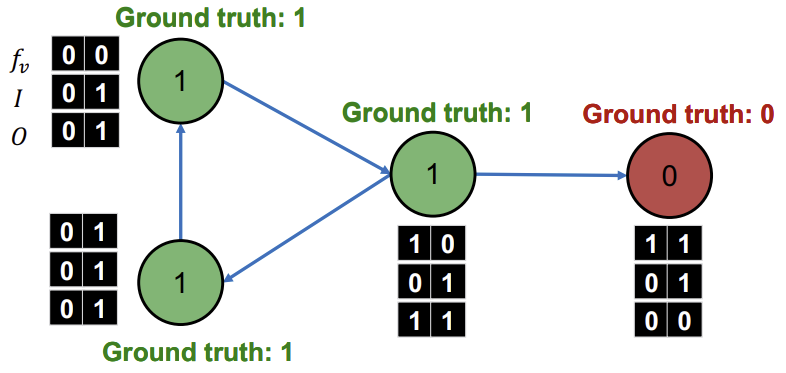
Summary

출처, 더 궁금하다면?
Stanford CS224W: ML with Graphs | 2021 | Lecture 5.2 - Relational and Iterative Classification