Why Graphs?
시계열 데이터, Sequence 데이터, tabular 데이터 등 세상에는 많은 종류의 데이터가 존재한다. 이들을 분석하고 예측하는 방법론에 대해서는 통계적 기법부터 Decision Tree기반, 혹은 nearest neighbor 기반 Clustering방식, Neural Network까지 이미 많은 곳에서 배워왔다.
하지만 이 방법들만으로는 처리하기 까다로운 형태의 데이터들도 존재한다. 그 중 이번 스터디에서 알아볼 것은 Graph이다. Graph는 실생활에서 존재하는 많은 현상/관계들을 표현할 수 있다.

왜 그래프를 표현하기 어려운가?
그래프를 이용한 머신러닝은 관계들을 명시적으로 모델링해서 좋은 퍼포먼스를 내는 것이 목적이다. 지금은 sequence나 grid(Matrix) 형식으로 딥러닝을 수행하지만, network(graph)는 표현하기가 더 까다롭다.
먼저 Network에는 Locality가 존재하지 않는다. Grid에서는 행과 열이 존재하여 index로 위치를 표현 가능한 반면, Network에는 관계만 존재한다.
둘째, 관계만 존재하므로, 다른 point들을 표현하기 위해 사용하는 reference point가 될 fixed node가 없다.
마지막으로 Graph는 dynamic하고 multimodal 한 경우도 있다.

Deep Learning in Graphs
Graph를 이용한 딥러닝의 목적은 Graph를 입력으로 하고, output으로 prediction을 내는 것이다. 이 과정에는 human feature engineering 없이 raw data(graph)를 넣으면 end-to-end로 결과가 도출 되는 것을 기대한다.

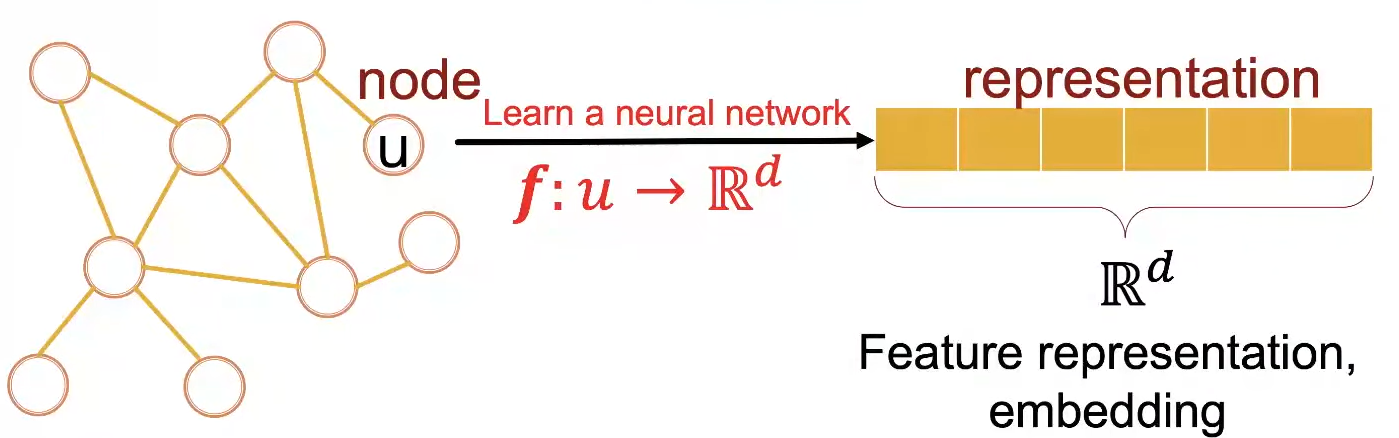
Representation Learning in Graphs
이러한 deep learing을 위해서는 graph를 적절한 형태로 변형하는 것이 중요하다. 예를 들어 관계가 많거나 유사한 node들을 가깝게 embedding 하는 등, Feature의 특징을 잘 표현하는 embedding으로 representation 해야한다.
Course Outline
아래는 앞으로 진행할 스터디 순서이다.

출처, 더 궁금하다면?
Stanford CS224W: Machine Learning with Graphs | 2021 | Lecture 1.1 - Why Graphs